A git tree is git’s internal representation for directories. Trees have entries which are either trees themselves, or blobs.
The general format is: First 4 bytes declaring the object type. In our case, those four bytes are “tree”, ASCII-encoded. Then comes a space, and then the entries, separated by nothing.
The exact format is the following. All capital letters are “non-terminals” that I’ll explain shortly.
where
Here’s an example. Say we have a directory with two files, called test and test2. The SHA of the directory is
(To reproduce this, the file test should contain the ASCII-encoded characters “hallo” (not \n-terminated), the file test2 should contain the ASCII-encoded characters “bla\n” (yes, \n-terminated)).
That is converted into the following object (uncompressed):

Finally, the file is deflated and stored on disk. For deflation, zlib is used. For my experiments I used the ruby zlip package. The following tiny script reads the tree from disk and inflates it, so you can look at it:
The general format is: First 4 bytes declaring the object type. In our case, those four bytes are “tree”, ASCII-encoded. Then comes a space, and then the entries, separated by nothing.
The exact format is the following. All capital letters are “non-terminals” that I’ll explain shortly.
tree ZN(A FNS)*where
- N is the NUL character
- Z is the size of the object in bytes
- A is the unix access code, ASCII encoded, for example> 100644 for a vanilla file.
- F is the filename, (I’m not sure about the encoding. It’s definitely ASCII-compatible), NUL-terminated.
- S is the 20 byte SHA hash of the entry pointed to, 20 bytes long.
Here’s an example. Say we have a directory with two files, called test and test2. The SHA of the directory is
f0e12ff4a9a6ba281d57c7467df585b1249f0fa5. You can see the SHA-hashes of the entries in the output of $ git cat-file -p f0e12ff4a9a6ba281d57c7467df585b1249f0fa5
100644 blob 9033296159b99df844df0d5740fc8ea1d2572a84 test
100644 blob a7f8d9e5dcf3a68fdd2bfb727cde12029875260b test2(To reproduce this, the file test should contain the ASCII-encoded characters “hallo” (not \n-terminated), the file test2 should contain the ASCII-encoded characters “bla\n” (yes, \n-terminated)).
That is converted into the following object (uncompressed):
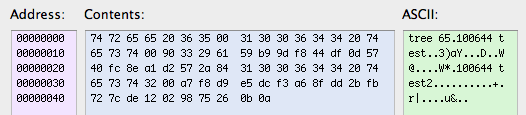
Finally, the file is deflated and stored on disk. For deflation, zlib is used. For my experiments I used the ruby zlip package. The following tiny script reads the tree from disk and inflates it, so you can look at it:
require 'zlib'
require 'fileutils'
File.open("objects/f0/e12ff4a9a6ba281d57c7467df585b1249f0fa5") { |f|
puts Zlib::Inflate.inflate(f.read)
}
I imagine the filenames are just a blob of bytes -- encodings are imposed at a higher level, but unix pretty much doesn't care what's in a filename other than / or nul
ReplyDeleteThere's a slight error in the post. It should be
ReplyDeletetree ZN(A FNS)*
Not "tree (ZNA FNS)*", because the Z is for the entire tree object, not each of its entries, and the null appears after it only once.
The example you posted follows the correct format, as the "tree 65." appears at the beginning, but no lengths appear before entries.
It is particularly tricky to note that the Unix access code of each entry is -not- preceded by a null. It follows straight upon the 20-byte SHA hash of the prior entry.
Thanks for the post!
Thanks John!
DeleteFixed it.
One more oddity: leading zeroes in the access code are skipped, so you have to look for the space instead of just reading 6 bytes. For example, the access code 040000 is stored as 34303030, or "40000". Seems like an odd way to save space, since Git only allows a very small number of permission combinations anyway (certainly few enough to fit in a single byte).
ReplyDeleteIs there a sorting order for the entries to make the hashes independent of disk structure?
ReplyDelete