Pharo does have something like full text search across all methods, and it works like this: Rightclick the text you'd like to search for, and choose "extended search" from the options. Then, choose "method source with it." A progress bar will appear, and you should get your answer within a minute. That has to do with the source not being loaded into Pharo at all times, it is read on demand out of the sources file.
However, the compiled sources are in memory from the start. While you can't meaningfully search compiled sources, you can search the string literals within. Again, rightclick the text you'd like to search for, and choose "extended search" from the options. But now, choose "method strings with it." That will bring up a list of all methods that contain the selected text as a string literal—instantly.
Wednesday, October 27, 2010
Tuesday, October 12, 2010
One of my most-hated methods in Pharo
TestCase>fail
^self assert: false
What's wrong? Well, I often write
self fail at the end of a unit test to remind myself that the test isn't yet done. Now, if I run the test, I care whether an assertion failed or whether the test solely failed. Of course I have no right to expect should detailed feedback from a test runner. But at least I shouldn't be misinformed. But that's exactly what happens. The TestRunner reports that an assertion failed if you call fail, even if none did.
Why's the Smalltalk debugger not focused on more in Smalltalk IDEs?
I can't help but wonder why Smalltalk's lovable trait of letting you develop in the debugger isn't leveraged far more by the IDEs. Suppose you just noticed that a method call doesn't have enough arguments. That is, you wrote this:
But you should have written:
Well now, that's a fantastic situation for refactoring, isn't it? You could automatically rename the method in the receiver, and you'd know quite precisely who that receiver is. Little of that is leveraged. But of course, if Smalltalk is to play any serious role in the future, we should play by our strengths.
Well, here's a strength: the most powerful debugger in any modern IDE.
self doSomething.
But you should have written:
self doSomethingWith: anArgument
Well now, that's a fantastic situation for refactoring, isn't it? You could automatically rename the method in the receiver, and you'd know quite precisely who that receiver is. Little of that is leveraged. But of course, if Smalltalk is to play any serious role in the future, we should play by our strengths.
Well, here's a strength: the most powerful debugger in any modern IDE.
Friday, October 8, 2010
A more robust doesNotUnderstand:?
Smalltalk makes it really convenient to write code in the debugger. So, how I often work is as follows:
Well, that's alright as far as it goes, but you can't work like that with
If you now call a non-existing method on an object of a thus modified class, you've built an endless recursion that is so close to the VM that you can't get into a debugger anymore.
Smalltalk's
Do you know a more robust implementation?
- Write a rough skeleton that calls "self fail" at some point.
- Write a unit test that calls the skeleton with real data.
- Finish the skeleton in the debugger, where I have test data right at hand to see if things work as intended.
Well, that's alright as far as it goes, but you can't work like that with
doesNotUnderstand: methods.doesNotUnderstand: aMessage
self fail.
If you now call a non-existing method on an object of a thus modified class, you've built an endless recursion that is so close to the VM that you can't get into a debugger anymore.
Smalltalk's
doesNotUnderstand: method is a dangerous superpower. And perhaps that's why just about nobody overwrites it in a standard Pharo image. Open problems
Do you know a more robust implementation?
- Non-existing calls inside the handler for such should be caught, I think.
- It should work nicely with code completion. (Code completion seems to be an integral part of just about every current approach to help programmer's productivity, so it better work nice.)
Friday, October 1, 2010
expandMacrosWith:
In Pharo, there's a very useful method
String>expandMacrosWith:, virtually without documentation. It's much like printf in C. I guess it's easily understood from a few examples, so here go:
"<1s> is replaced by the first argument, a string.
<n> is a newline, <t> is a tab.
% escapes brackets."
'<1s><n><t>%<inject><n><t>^<1s>' expandMacrosWith: 'player'
➔
'player
<inject>
^player'
"p calls printString":
'<1p>' expandMacrosWith: #(1 2 3)
➔
'#(1 2 3)'
"? prints one string or another, depending on a Boolean"
'Dear <1?Mr:Mrs> <2s>, your contract has expired.'
expandMacrosWith: false with: 'Smith'
➔
'Dear Mrs Smith, your contract has expired.'
Wednesday, September 29, 2010
Pharo dojo in Bern, October 23–24
There will be a Pharo dojo in Bern. The announcement reads:
We will organize a joint Pharo sprint / Moose dojo during October 23-24, in Bern (at the Software Composition Group, University of Bern). There will be free food and drinks!
Some action points are mentioned on the dedicated page (of course, other ideas and interests are welcome as well).
For planning purposes, please let me, Tudor Girba, know if you will attend.
Monday, September 27, 2010
Dependency injection aids copy and paste coding
In the presence of good documentation or sample code, I love to copy and paste directly out of the documentation or even unit tests, straight into my code.
For example, I was wondering how to add an instance variable to a class in Pharo Smalltalk. Well, I just search my code base for occurrences of addInstanceVariable, and I find this test:
Well, that's great, the first few lines are what I need. Some more browsing shows that line 6 is deeply irrelevant for me: the test uses a highly artificial way of executing the test, different from the canonical one.
Is any of that surprising? Not really. There's some papers establishing that this is how a lot of people work: forking work off sample code, but only if it's complex enough to match the use case (cite?).
I think it has an interesting implication for writing unit tests: They should be as close as possible to the intended end user usage. In the example above, my hunch is that the unit test wasn't written in the way that the end user would use the library, because the author feared side effects.
I think here we see one of the great strengths of dependency injection: by moving the part of the unit test that avoids side effects to another level of abstraction, the unit test itself can look exactly as if it had side effects, and thus can serve better as a basis for new work.
For example, I was wondering how to add an instance variable to a class in Pharo Smalltalk. Well, I just search my code base for occurrences of addInstanceVariable, and I find this test:
testAddInstanceVariable
| refactoring |
refactoring := AddInstanceVariableRefactoring
variable: 'asdf'
class: RBTransformationRuleTest.
self executeRefactoring: refactoring.
self assert: ((refactoring model classNamed:
#RBTransformationRuleTest)
directlyDefinesInstanceVariable: 'asdf')
Well, that's great, the first few lines are what I need. Some more browsing shows that line 6 is deeply irrelevant for me: the test uses a highly artificial way of executing the test, different from the canonical one.
Is any of that surprising? Not really. There's some papers establishing that this is how a lot of people work: forking work off sample code, but only if it's complex enough to match the use case (cite?).
I think it has an interesting implication for writing unit tests: They should be as close as possible to the intended end user usage. In the example above, my hunch is that the unit test wasn't written in the way that the end user would use the library, because the author feared side effects.
I think here we see one of the great strengths of dependency injection: by moving the part of the unit test that avoids side effects to another level of abstraction, the unit test itself can look exactly as if it had side effects, and thus can serve better as a basis for new work.
Circular problem solving in computer science
Here's the rules: Find a genuine problem in a framework called X. Then write your solution in framework Y that depends on X. Then, rewrite X using Y such that the problem goes away.
Because rewriting of X depends via Y on some older version of X, I give bonus points for using a framework that allows calling older versions of X from within X.
Because rewriting of X depends via Y on some older version of X, I give bonus points for using a framework that allows calling older versions of X from within X.
Wednesday, September 22, 2010
Three degrees of inversion of control.
Inversion of control is a paradigm by Martin Fowler that advocates for separating things that don't belong together during object creation.
What exactly should be split from what? Different frameworks answer the question slightly differently. They do at least 1 of these three:
All three are compatible with one another. Can they be combined in practice? I'm working on it …
What exactly should be split from what? Different frameworks answer the question slightly differently. They do at least 1 of these three:
- Eliminate direct constructor calls. All dependency injection frameworks do that.
- Strictly separate business logic from object creation. Google Guice, among others, allows that, but doesn't enforce that.
- Eliminate all static references. Newspeak makes all lookups dynamic, thereby eliminating global state.
All three are compatible with one another. Can they be combined in practice? I'm working on it …
Thursday, July 22, 2010
In unit tests, why are failures yellow but errors red?
It's confusing, isn't it? Errors are displayed red, which looks scary, while failures are displayed yellow, which looks inviting. But, debugging a test failure, you don't get a trace of a clue what caused the failure. While debugging an error, you have the stack trace right there and know exactly where to look.
When SUnit lists yellow and red failed unit tests, I invariably start with the red ones. They're usually easier to fix.
When SUnit lists yellow and red failed unit tests, I invariably start with the red ones. They're usually easier to fix.
Tuesday, June 22, 2010
Book tip: Computing the mind
I'd like to discuss why, without having finished the book yet, I hand over heels love the book: Computing the mind, subtitled "How the mind really works", by Shimon Edelmann. I have to admit that I didn't have the highest hopes when I opened the book. I went so far as to skip the first couple of pages, to get to the fun parts a bit quicker. As I write these blog post, page 1 lies open on my desk, and it's the most beautiful start a non-fiction book could hope to offer:
And then, on page 78, we get this teaser for what's to come later:
He had me long before page 78, though. He quotes Karl Popper throughout the book. This book is amazing in clarity, it's funny, and it's mind-opening.
If you are reading this in the first couple of decades of the third millennium of the common era, chances are that (1) the human brain is the most complex toy you'll ever come near, let alone get to play with, and (2) you're trapped inside one for the foreseeable future.
And then, on page 78, we get this teaser for what's to come later:
Claim: the brain is a programmable digital computer. If this were true, the brain would be like hardware to the mind's software. This claim does not stand up to scrutiny, mainly because in the brain it is not possible to separate the "program" from the architecture that executes it. It is very important to remember, however, that a digital computer can simulate the operation of a brain (because a digital computer can simulate any physical system down to an arbitrary precision), and hence the mind. The ramifications of the realization that the mind is what the brain does are far-reaching and profound; I shall describe and discuss them in later chapters.
He had me long before page 78, though. He quotes Karl Popper throughout the book. This book is amazing in clarity, it's funny, and it's mind-opening.
Sunday, May 23, 2010
Friendly advice from Eric S Raymond
My favorite quote from "The cathedral and the bazaar," p. 207:
I love the book, but I think the first two essays would have been enough to read, that's "The cathedral and the bazaar" and "homesteading the noosphere." The others are far from neutral and not full of insight like the first two. The first two are an insightful analysis of the psychology and culture of hackerdom.
If you're attracted to hacking because you don't have a life, that's okay too---at least you won't have trouble concentrating. Maybe you'll get a life later on.
I love the book, but I think the first two essays would have been enough to read, that's "The cathedral and the bazaar" and "homesteading the noosphere." The others are far from neutral and not full of insight like the first two. The first two are an insightful analysis of the psychology and culture of hackerdom.
Tuesday, May 4, 2010
The burden of the reviewer
The paper I'm reviewing treats an interesting topic without much love. I'm getting sick of reading other people's papers. If this goes on, I'll just write my own papers.
By the way, I'm still taking really long for reviewing. An hour of work and I'm on page … 2.
By the way, I'm still taking really long for reviewing. An hour of work and I'm on page … 2.
Thursday, March 25, 2010
Git tree objects, how are they stored?
A git tree is git’s internal representation for directories. Trees have entries which are either trees themselves, or blobs.
The general format is: First 4 bytes declaring the object type. In our case, those four bytes are “tree”, ASCII-encoded. Then comes a space, and then the entries, separated by nothing.
The exact format is the following. All capital letters are “non-terminals” that I’ll explain shortly.
where
Here’s an example. Say we have a directory with two files, called test and test2. The SHA of the directory is
(To reproduce this, the file test should contain the ASCII-encoded characters “hallo” (not \n-terminated), the file test2 should contain the ASCII-encoded characters “bla\n” (yes, \n-terminated)).
That is converted into the following object (uncompressed):

Finally, the file is deflated and stored on disk. For deflation, zlib is used. For my experiments I used the ruby zlip package. The following tiny script reads the tree from disk and inflates it, so you can look at it:
The general format is: First 4 bytes declaring the object type. In our case, those four bytes are “tree”, ASCII-encoded. Then comes a space, and then the entries, separated by nothing.
The exact format is the following. All capital letters are “non-terminals” that I’ll explain shortly.
tree ZN(A FNS)*where
- N is the NUL character
- Z is the size of the object in bytes
- A is the unix access code, ASCII encoded, for example> 100644 for a vanilla file.
- F is the filename, (I’m not sure about the encoding. It’s definitely ASCII-compatible), NUL-terminated.
- S is the 20 byte SHA hash of the entry pointed to, 20 bytes long.
Here’s an example. Say we have a directory with two files, called test and test2. The SHA of the directory is
f0e12ff4a9a6ba281d57c7467df585b1249f0fa5. You can see the SHA-hashes of the entries in the output of $ git cat-file -p f0e12ff4a9a6ba281d57c7467df585b1249f0fa5
100644 blob 9033296159b99df844df0d5740fc8ea1d2572a84 test
100644 blob a7f8d9e5dcf3a68fdd2bfb727cde12029875260b test2(To reproduce this, the file test should contain the ASCII-encoded characters “hallo” (not \n-terminated), the file test2 should contain the ASCII-encoded characters “bla\n” (yes, \n-terminated)).
That is converted into the following object (uncompressed):
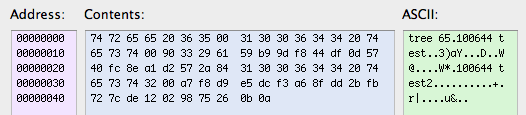
Finally, the file is deflated and stored on disk. For deflation, zlib is used. For my experiments I used the ruby zlip package. The following tiny script reads the tree from disk and inflates it, so you can look at it:
require 'zlib'
require 'fileutils'
File.open("objects/f0/e12ff4a9a6ba281d57c7467df585b1249f0fa5") { |f|
puts Zlib::Inflate.inflate(f.read)
}Monday, March 22, 2010
Saturday, March 20, 2010
You can't cast Object[] to String[] in Java
Consider this snippet:
That gives a
which prints:
String[] str = (String[]) new Object[] { "Bla!"};.That gives a
ClassCastException. The short version of an explanation: an array instantiated by new Object[] is of a different class than one by new String[]. For the full glory of that fact, please see the Java Language Specification. As a teaser, I'll quote this snippet and its output from it:class Test {
public static void main(String[] args) {
int[] ia = new int[3];
System.out.println(ia.getClass());
System.out.println(ia.getClass().getSuperclass());
}
}
which prints:
class [Iclass java.lang.Object.
Thursday, March 18, 2010
Thick tech books
James Hague:
Well, that about explains why tech books suck so badly.
"In order for a book to sell," said my publisher, "it's got to be thick. 600 pages thick."
Well, that about explains why tech books suck so badly.
How to test post-conditions
A pretty good student, Joshua Muheim, just asked me what the simplest way was to check postconditions. And my answer was the following:
Joshua, this is a research question! To the best of my knowledge, currently and in practice, developers use steamroller tactics to check postconditions. The standard way to verify that the LHC works as intended, in a method
That is, you copy whatever you intend to change and then compare new with old value. It isn’t difficult to imagine that this can lead to trouble if whatever you want to change isn’t cloneable. And of course it isn't possible to switch off the overhead of these assertions.* And that’s where Histoory (by Pluquet et al) comes to the rescue. Not only does it work independent of the cloneability, it also provides a much cleaner syntax:
Alas, it isn’t in the latest flavor of any programming language, so I truly hope that Histoory will make it into Pharo :).
* I added this sentence after Joshua's correct observation of this problem.
Joshua, this is a research question! To the best of my knowledge, currently and in practice, developers use steamroller tactics to check postconditions. The standard way to verify that the LHC works as intended, in a method
exterminate on a class EarthPopulation:exterminate
| oldSize |
oldSize := self size.
LHC switchOn.
self size should < oldSize.
That is, you copy whatever you intend to change and then compare new with old value. It isn’t difficult to imagine that this can lead to trouble if whatever you want to change isn’t cloneable. And of course it isn't possible to switch off the overhead of these assertions.* And that’s where Histoory (by Pluquet et al) comes to the rescue. Not only does it work independent of the cloneability, it also provides a much cleaner syntax:
exterminate
[LHC swithOn]
postCond: [:old | old size should < self size]
Alas, it isn’t in the latest flavor of any programming language, so I truly hope that Histoory will make it into Pharo :).
* I added this sentence after Joshua's correct observation of this problem.
Tuesday, March 16, 2010
Book on algorithm design
Recently, Sedgewick's algorithms book slipped through my hands again. It's a great book. I'd just like to point to a newer algorithms book that is thinner, and funner to read, and if you just want to browse for an hour or two, this is surely worth your while. That's Algorithm design, by Jon Kleinberg, and Éva Tardos.
Monday, March 15, 2010
Software merging, commit messages
What is the intent of a change? How do you merge conflicting changes? The current state of the art is dire. There's a survey, A state-of-the-art survey on software merging , but it's summary may be that there's no silver bullet to automated merging without understanding the intent of a commit.
How do you understand the intent of a commit? The best technique I am aware of today is … having the author provide a clear description of his intent. There's a paper about that, quite worth your while: Semantic patches considered helpful.
I told you that the situation is dire, didn't I?
How do you understand the intent of a commit? The best technique I am aware of today is … having the author provide a clear description of his intent. There's a paper about that, quite worth your while: Semantic patches considered helpful.
I told you that the situation is dire, didn't I?
Sunday, February 28, 2010
Distance measure between software artifacts
There's currently some interest in software visualization, which tries to speed up your understanding of source code by leveraging your brain's great ability to discern patterns in images. Below is shot of Codemap, visualizing something.

To draw a map such as the above, you need an underlying metric that tells you how far apart the code artifacts should be. (You probably won't be able to draw a map where the distances are exactly what you want them to be, but you may get close.) Now, what is used as a metric between software artifacts (islands, in the above image)? Codemap uses the vocabulary of the artifact, that is: artifacts that use many same words will end up closer together in the overall drawing.
A botfly moves along a herd of cattle. It finds every of the beasts hospitable, but it can't live without a herd. Thus, Richard Dawkins calls the herd the botfly's "Archipelago" (in The greatest show on earth, p. 253). This inspires me to a metric which is supposed to measure similarity of software artifacts. The idea is to assume that if two artifacts are hospitable to the same code snippet, then they should provide similar environments. Thus, you could measure how in the evolution of a software program, snippets wandered from one place to another, and assume that whenever a code snippet is moved from one artifact to another, these two artifacts increase in our metric's similarity.
It seems difficult to bring forth evidence that software maps aid understanding in the first place, thus I wouldn't know how to show that a metric like the one outlined above is any better than a comparison of metrics. Yet, there's some momentum in the field, so I'll save up the idea for a point in time when more light will be shed on the benefits of software visualization.
Saturday, January 9, 2010
On Erwann Wernli's idea of having the VM take care of dependency injection
My dear friend Erwann asks in his blog whether dependency injection should not be the task of the virtual machine. He considers code like this:
List l = new ArrayList();He then notices (correctly, to my mind), that this statement contains more detail than the developer meant to express. "Whether the list is a new one or not, I don’t care, all I need is an empty one," Erwann writes. Fair enough.
There's real problems connected with the observation. The Java specification rules that new has to allocate a new object. Hence, the method
static void slack() { new Object(); return;}cannot be optimized into a nop. Now, I believe you've already thought of a code snippet that cannot be optimized due to this rule. And of course it gets worse if the language forces us to use new all the time. it is the only way to get an object, even though we would have been fine with an old one, should it fulfill our criteria.
Here's the solution he proposes:
List l = obtain list ( size=0 );To undo the awkwardness, he proposes hiding this monstrum in syntactic sugar, although it isn't clear to me what the sugar should look like in this instance.
Besides avoiding the new operator, his proposal leaves the concrete type of variable l open. He now proposes that depending on the "context," the VM can do voodoo to determine exactly which class may be most appropriate at the point in time. As an example, he cites changing the default FileInputStream to a zipped version of itself, as disk space runs low.
I find his thinking interesting, because it asks the good old question of who's responsible for what in programming. Having the machine figure stuff out for you is great if the figuring out is easy or secondary. Everyone loves Ruby's ActiveRecord, which creates the database table belonging to an entity class of yours all by itself. But choosing the right kind of a list? That's harder. There's a disadvantage to having the machine figure stuff out for you: your program gains in being opaque. The text-file that stores your program code would diverge further from the code to be executed at run time, because important decisions about the code are delayed to the run-time of the program. Since us humans can only see text, this is a real drawback.
I'm obviously sceptical to ubiquitious dependency injection, and I'm not the only one. Here's what Russ Olsen has to say about the matter (In his book Design Patterns in Ruby):
The best way to go wrong with any of the object creation techniques that we have examined … is to use them when you don't need them. Not every object needs to be produced in a factory. In fact, most of the time you will want to create most of your objects with a simple MyClass.new. … Remember, chances are You Ain't Gonna Need It.Well, we have to balance our skepticism against what voodoo may bring us. Suffice it to say that I don't really believe that I want the VM to have any say in whether I zip my files or not. If I write a file to the disk that then the bash will assume to be a plain text email message, it better not be zipped on 5 % of my clients' computers. Another advantage of the voodoo is that we may also get to re-using objects that are laying around anyhow, waiting to be garbage collected. There's charm to that idea, although I wonder if the picture is as rose as Erwann paints it. After all, you'd need to find an object to be disposed first. Object Pooling sucks up memory and CPU cycles for their management.
Let me summarize that I'm skeptical about the solution that is proposed. Nonetheless, Erwann raises legitimate and important questions, such as: Don't our languages force the developer to supply and commit to more detail than the developer wishes? A mismatch between the mental model of the developer and the programming language is a flaw that deserves our tending to.
There's one little afterthought. Erwann claims that the mismatch he identified can be tackled only by making both language and VM aware of the problem. I believe the strength and beauty of Smalltalk is to come a far way in allopwing new ways of doing things, without having to dig to the VM and the language (See the blog post by Benjamin Pollack: Your Language Features Are My Libraries). Well, I think that Newspeak's late binding of class names could implement all of Erwann's ideas in a library. Here's the idea: If you type Array.new, then you may expect Array to point to a specific and global class in a namespace that is the same everywhere. What if all lookups had to go through a "lobby," as it were, and each module could not demand the module, it would have to be passed. Then, we could have the lobby figure out what List.new is supposed to mean, and have it be context-dependent. (Newspeak is a dream of a programming language. It breaks my heart to see how it isn't used widely. See the Wikipedia article for an overview.)
Summary
Programming languages do not currently reflect the mental model of the developer in instructions as easy as
List l = new ArrayList();They specify more details than the programmer wishes to, and as a result, optimizations and opportunities for automation are lost. I suspect that Newspeak would be a great platform for experiments, and I'd like to thank Erwann Wernli for sharing his concerns. His blog is great by the way. Please go and read it!
Here is Erwann Wernli's article: Erwann Wernli: Should DI and GC be unified?.
Subscribe to:
Posts (Atom)